Real-World Example#
This guide shows you how to model a scene from HyperSuprimeCam (HSC) data as a hyperspectral image cube.
# Import Packages and setup
import matplotlib.pyplot as plt
import jax.numpy as jnp
import scarlet2 as sc2
Load the Data#
We load the example data set (here an image cube from HSC with 5 bands) and a detection catalog. If such a catalog is not available, you can use the detection method that comes with scarlet2, or packages like SEP and photutils.
To make tests like this one convenient, we provide a HuggingFace data set for scarlet2. To download it locally, you need to pip install huggingface_hub:
from huggingface_hub import hf_hub_download
filename = hf_hub_download(
repo_id="astro-data-lab/scarlet-test-data",
filename="hsc_cosmos_35.npz",
repo_type="dataset"
)
file = jnp.load(filename)
data = file["images"]
channels = [str(f) for f in file["filters"]]
weights = 1 / file["variance"]
psf = file["psfs"]
# Read the catalog
# Note: y/x convention!
catalog = jnp.array([(src["y"], src["x"]) for src in file["catalog"]])
Warning
Coordinates in scarlet are given in the C/numpy notation (y,x) as opposed to the more conventional (x,y) ordering.
Define the Observation#
An Observation stores several data arrays. In addition to the actual science image cube, you can and usually must provide weights for all elements in the data cube, an image cube of the PSF model (one image for each channel), an astropy.wcs.WCS structure to translate from pixel to sky coordinates, and labels for all channels.
The observation stores these meta-data in the data structure Frame as the attribute .frame (similar to the header in a FITS file).
obs = sc2.Observation(data, weights=weights, psf=psf, channels=channels, name="HSC")
Observation validation results:
[000] INFO Number of channels in the observation matches the data.
[001] INFO Data and weights have the same shape.
[002] INFO Observation.weights in the observation are finite and non-negative.
[003] INFO Data in the observation are finite where weights are greater than zero.
[004] INFO PSF is 3-dimensional.
[005] INFO Number of PSF channels matches the number of data channels.
[006] WARN PSF centroid is not the same in all channels. | Context={'psf_centroid': Array([[ 0.04197121, -0.01779556, 0.0002327 , 0.04332542, 0.06899071],
[ 0.09050751, 0.01180649, -0.03284836, 0.08525848, -0.00099373]], dtype=float32)})
Note the validation results, which are automatically generated and act as early warning signs.
We’ll see more of these validation tests later in this notebook.
Here the check number 006 indicates that the PSF is not centered at the same position for all channels.
The offsets are minor, so we’ll proceed, but we’re going to come back to this issue at the end.
For additional information about automatic validation (including how to switch them off), check out the “Validation” section of the documentation.
Display the Image Cube#
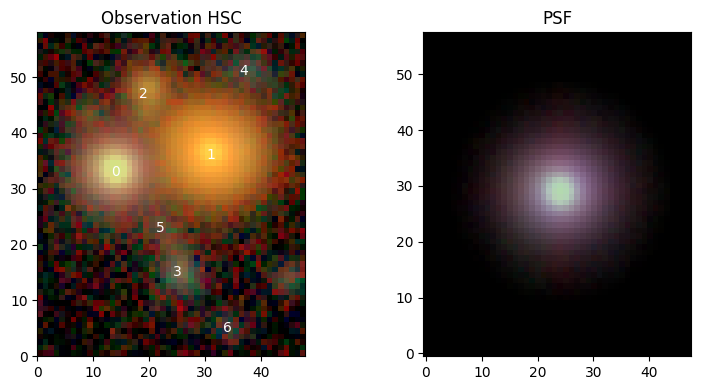
We can now make use of the plotting function scarlet2.plot.observation() to create a RGB image of our data.
We’re going to use the AsinhAutomaticNorm, which scales the observed data by a \(\mathrm{sinh}^{-1}\) function that is automatically tuned to reveal both the noise level and the highlights, to create a color-consistent RGB image.
norm = sc2.plot.AsinhAutomaticNorm(obs)
sc2.plot.observation(obs, norm=norm, show_psf=True, add_peaks=catalog);
Define the Model Frame#
scarlet2 needs another Frame, which describes the properties of the model of the sky you seek to fit. Given one or several observations, scarlet2 can make an educated guess what model frame would be best:
model_frame = sc2.Frame.from_observations(obs)
print(model_frame)
Frame(
bbox=Box(shape=(5, 58, 48), origin=(0, 0, 0)),
psf=GaussianPSF(morphology=GaussianMorphology(size=0.7, ellipticity=None)),
wcs=WCS Keywords
Number of WCS axes: 2
CTYPE : 'RA---CAR' 'DEC--CAR'
CRVAL : np.float64(180.0) np.float64(0.0)
CRPIX : np.float64(25.0) np.float64(30.0)
PC1_1 PC1_2 : np.float64(1.0) np.float64(0.0)
PC2_1 PC2_2 : np.float64(0.0) np.float64(1.0)
CDELT : np.float64(-0.000278) np.float64(0.000278)
NAXIS : 48 58,
channels=['g', 'r', 'i', 'z', 'y']
)
If only one observation is given (as above), we assume that bands and pixel locations are identical between the model and the observation. Because we have ground-based images, we need to account for different PSFs in each band, which means the model frame needs to define a reference PSF that is sufficiently narrow. Our default is a minimal Gaussian PSF that is barely well-sampled (standard deviation of 0.7 pixels) as the PSF reference.
Because we didn’t provide a WCS for the observation, the code will automatically create a dummy WCS with a 1-arcsec pixel scale and an intentionally unsual pseudo-Euclidean Carée projection.
If the model frame should have other properties, they can be overwritten through arguments to scarlet2.Frame.from_observations().
But what’s the point of the model frame? Why is it needed at all?
Tip
To fit multiple images with different PSF, different bands, different resolutions, etc…, we must define a model that is superior in all of these aspects, so that each observation can be computed from the model by a degradation operation, the so-called “forward operator”. The point of joint modeling is to find one superior model of the sky that is consistent with all observations.
In scarlet2, the forward operators are implemented as Renderer, which contains, e.g., PSF difference kernels and resampling transformations. It gets created when calling ~scarlet2.Observation.match (which is normally done only when needed, but we can call it explicitly to see its effect):
obs.match(model_frame)
print(obs.renderer)
ConvolutionRenderer(kernel_fft=c64[5,96,33], shift=f32[2])
Initialize Sources#
You now need to define sources that are going to be fit. The full model, which we call a Scene, is a collection of Sources. Each source contains at least one Component, and each of those is defined by a center, spectrum, and morphology. You can have as many sources in a scene, or as many components in a source, as you want. To represent stars or other point sources, we provide the class PointSource, which adopts the PSF of the model frame as the morphological model of the source.
Adding sources to a scene is easy. You create the scene (as a python context with the with keyword) and then create a source inside of that context. It will automatically be added to the overall scene model. But now we have to decide what the initial values of spectrum and morphology should be. You can choose them as you see fit, but we also provide convenience methods. For instance scarlet2.init.pixel_spectrum() takes the spectrum of one pixel (typically the center pixel), and scarlet2.init.from_gaussian_moments() measures the spectrum and morphology by measuring the 2nd moments and creating an elliptical Gaussian to match those. But we also have a robust wavelet-based initialization method, scarlet2.init.hierarchical_sources(), which we generally recommend for speed, flexibility, and robustness:
with sc2.Scene(model_frame) as scene:
infos = sc2.init.hierarchical_sources(obs, K=2, scales=[1,2,3], strict=True, catalog=catalog)
for sinfo in infos:
sc2.Source(sinfo.center, sinfo.spectrum, sinfo.morphology)
The method finds peaks at multiple scales and merges them if they overlap, which makes the method well suited for blended scenes. For more details, have a look at our detection guide.
Sometimes, we might have additional information about the scene, with which we could customize the modeling. Let’s assume that we know that source 0 is a star. We should therefore instantiate that source with a PointSource, either by modifying the cell above, or by overwriting the specific entry in the source list:
# we know source 0 is a star:
# replace current non-parametric source with a point source
idx = 0
with scene:
center = catalog[idx]
spectrum = sc2.init.pixel_spectrum(obs, center, correct_psf=True)
scene.sources[idx] = sc2.PointSource(center, spectrum)
Let’s check what we have in scene:
sc2.plot.scene(
scene,
obs,
norm=norm,
show_model=True,
show_rendered=True,
show_observed=True,
show_residual=True,
add_boxes=True,
);
print(scene)
Scene(
frame=Frame(
bbox=Box(shape=(5, 58, 48), origin=(0, 0, 0)),
psf=GaussianPSF(morphology=GaussianMorphology(size=0.7, ellipticity=None)),
wcs=WCS Keywords
Number of WCS axes: 2
CTYPE : 'RA---CAR' 'DEC--CAR'
CRVAL : np.float64(180.0) np.float64(0.0)
CRPIX : np.float64(25.0) np.float64(30.0)
PC1_1 PC1_2 : np.float64(1.0) np.float64(0.0)
PC2_1 PC2_2 : np.float64(0.0) np.float64(1.0)
CDELT : np.float64(-0.000278) np.float64(0.000278)
NAXIS : 48 58,
channels=['g', 'r', 'i', 'z', 'y']
),
sources=[
PointSource(
center=f32[2],
spectrum=f32[5],
morphology=GaussianMorphology(size=0.7, ellipticity=None),
bbox=Box(shape=(5, 11, 11), origin=(0, 28, 9)),
components=[],
component_ops=[]
),
Source(
center=f32[2],
spectrum=f32[5],
morphology=f32[25,25],
bbox=Box(shape=(5, 25, 25), origin=(0, 24, 19)),
components=[],
component_ops=[]
),
Source(
center=f32[2],
spectrum=f32[5],
morphology=f32[11,11],
bbox=Box(shape=(5, 11, 11), origin=(0, 42, 14)),
components=[],
component_ops=[]
),
Source(
center=f32[2],
spectrum=f32[5],
morphology=f32[14,13],
bbox=Box(shape=(5, 14, 13), origin=(0, 8, 19)),
components=[],
component_ops=[]
),
Source(
center=f32[2],
spectrum=f32[5],
morphology=f32[11,11],
bbox=Box(shape=(5, 11, 11), origin=(0, 46, 33)),
components=[],
component_ops=[]
),
Source(
center=f32[2],
spectrum=f32[5],
morphology=f32[7,7],
bbox=Box(shape=(5, 7, 7), origin=(0, 19, 19)),
components=[],
component_ops=[]
),
Source(
center=f32[2],
spectrum=f32[5],
morphology=f32[11,11],
bbox=Box(shape=(5, 11, 11), origin=(0, 0, 28)),
components=[],
component_ops=[]
)
]
)
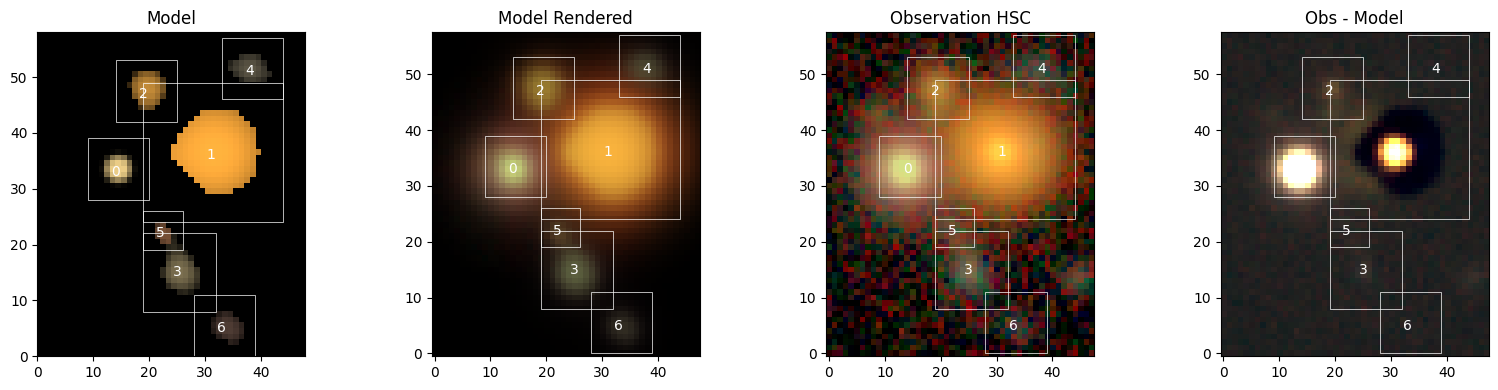
scene contains the frame and the list sources. Each source “lives” in a smaller box and is then placed into the larger scene. The model of object 0 assumes the simple Gaussian shape of the model PSF, which is the internal representation of a point source. All others are standard Sources. The data portions in these models are listed as, e.g., f32[11,11], which denotes an image array of 11x11 pixels. The size of these boxes was determined by the initialization method above.
But these initial choices are not great. So, we now have to…
Fit the Model#
The Scene class holds the list of sources and creates a model of the sky that (like any Module) can be evaluated, which allows us to determine the log-likelihood of the data given the model:
scene_array = scene() # evaluate the model
print("Initial likelihood:", obs.log_likelihood(scene_array))
Initial likelihood: -3234693.0
But as most of us don’t think in terms of likelihoods, we can also compute the goodness of fit of the model, which is identical to the log-likelihood up to a constant but much easier to interpret: It’s the average chi^2 over all pixels with non-zero weights.
print("Avg. chi^2:", obs.goodness_of_fit(scene_array))
Avg. chi^2: 462.91687
You can now write your own fitter or sampler, but we provide the machinery for that as well. We’re using optax for the optimization. First we need to define which Parameters of the model should be optimized. A model parameter that is not included will not be updated. For each Parameter, you need to specify a name, stepsize, and, optionally, differentiable constraints or prior distributions from numpyro. Below is our recommended configuration:
from functools import partial
from numpyro.distributions import constraints
# best step size for parameters with a relative "uncertainty":
# big/bright sources adjust more quickly
spec_step = partial(sc2.relative_step, factor=0.05)
morph_step = 0.1
with sc2.Parameters(scene):
for i in range(len(scene.sources)):
# because we want the spectrum parameter to be constrained,
# we need to ensure that their initialization satisfies the constraint
tiny = 1e-6
spectrum = scene.sources[i].spectrum
if (spectrum <= 0).any():
scene.sources[i] = scene.sources[i].replace("spectrum", jnp.maximum(spectrum, tiny))
sc2.Parameter(
scene.sources[i].spectrum,
name=f"spectrum:{i}",
constraint=constraints.positive,
stepsize=spec_step,
)
if i == 0:
sc2.Parameter(scene.sources[i].center, name=f"center:{i}", stepsize=0.1)
else:
# same for [0,1] constrained morphology
morph = spectrum = scene.sources[i].morphology
if ((morph <= 0) | (morph >= 1)).any():
scene.sources[i] = scene.sources[i].replace("morphology", jnp.clip(morph, tiny, 1-tiny))
sc2.Parameter(
scene.sources[i].morphology,
name=f"morph:{i}",
constraint=constraints.unit_interval,
stepsize=morph_step,
)
The parameters are now attached to scene, and can be accessed with scene.parameters.
Now we can run the fitting method:
maxiter = 1000
scene_ = scene.fit(obs, max_iter=maxiter, e_rel=1e-4)
Fit validation results for observation HSC:
[000] INFO The model fit is good. | Context={'chi2': Array(1.343877, dtype=float32)})
[001] WARN The chi-square in the box for source 0 is acceptable, but not optimal. | Context={'chi2_in': Array(2.3528464, dtype=float32), 'source': 0})
[002] INFO The chi-square in the border for source 0 is good. | Context={'chi2_border': Array(1.0353976, dtype=float32), 'source': 0})
[003] WARN The chi-square in the box for source 1 is acceptable, but not optimal. | Context={'chi2_in': Array(1.6471052, dtype=float32), 'source': 1})
[004] INFO The chi-square in the border for source 1 is good. | Context={'chi2_border': Array(1.1005018, dtype=float32), 'source': 1})
[005] INFO The chi-square in the box for source 2 is good. | Context={'chi2_in': Array(0.9612913, dtype=float32), 'source': 2})
[006] INFO The chi-square in the border for source 2 is good. | Context={'chi2_border': Array(1.1851155, dtype=float32), 'source': 2})
[007] INFO The chi-square in the box for source 3 is good. | Context={'chi2_in': Array(1.0109608, dtype=float32), 'source': 3})
[008] INFO The chi-square in the border for source 3 is good. | Context={'chi2_border': Array(0.93865836, dtype=float32), 'source': 3})
[009] INFO The chi-square in the box for source 4 is good. | Context={'chi2_in': Array(0.8598195, dtype=float32), 'source': 4})
[010] INFO The chi-square in the border for source 4 is good. | Context={'chi2_border': Array(1.0735675, dtype=float32), 'source': 4})
[011] INFO The chi-square in the box for source 5 is good. | Context={'chi2_in': Array(1.0109007, dtype=float32), 'source': 5})
[012] INFO The chi-square in the border for source 5 is good. | Context={'chi2_border': Array(1.0060037, dtype=float32), 'source': 5})
[013] INFO The chi-square in the box for source 6 is good. | Context={'chi2_in': Array(0.9918016, dtype=float32), 'source': 6})
[014] INFO The chi-square in the border for source 6 is good. | Context={'chi2_border': Array(1.0863719, dtype=float32), 'source': 6})
Interact with Results#
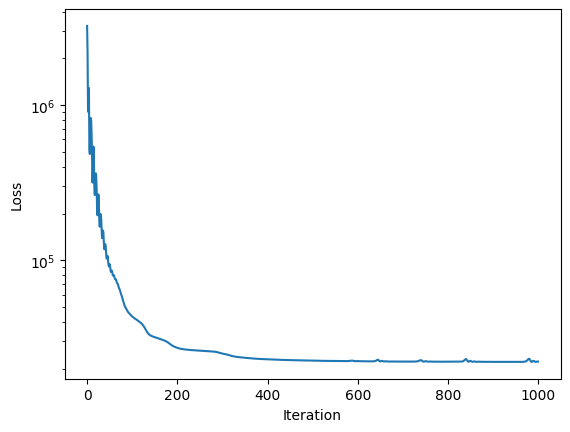
The updated source models are now available in scene_. It now carries the attribute fit_info, so that we can plot the loss curve.
We can also evaluate the entire scene and compute the now much improved goodness of fit:
plt.semilogy(scene_.fit_info['loss'])
plt.ylabel('Loss')
plt.xlabel('Iteration')
plt.show()
scene_array = scene_()
print("Optimized chi^2:", obs.goodness_of_fit(scene_array))
Optimized chi^2: 1.343877
Display Full Scene#
sc2.plot.scene(
scene_,
obs,
norm=norm,
show_model=True,
show_rendered=True,
show_observed=True,
show_residual=True,
add_boxes=True,
);
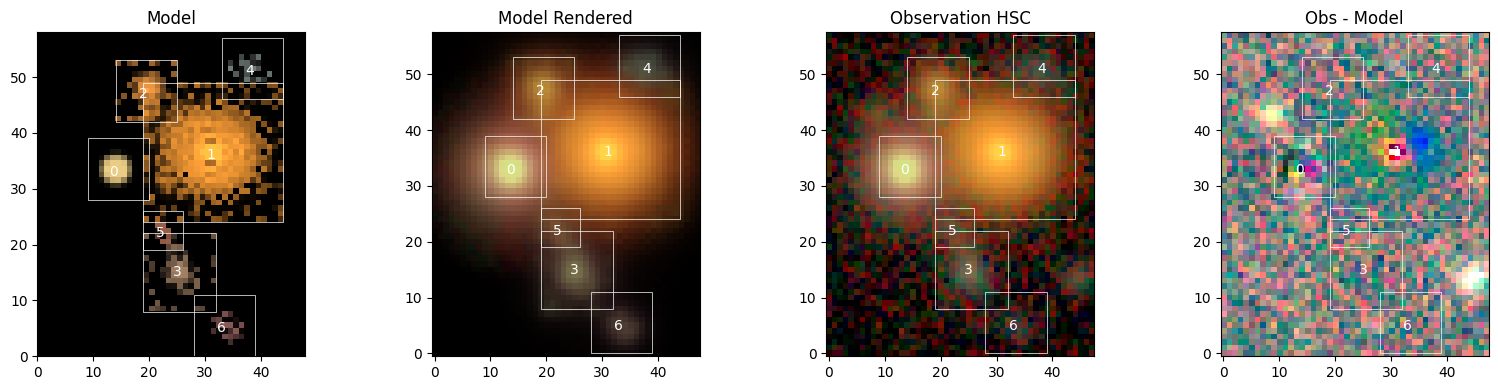
The fit is overall quite good, with low residuals, but it’s not perfect. Let’s investigate…
Access All Sources#
Individual sources can be accessed and evaluated as well, but we have to decide in which frame we want to see them. There are three options:
# Get models for source 1
source = scene_.sources[1]
# in its own source box (indicated by the white boxes in the figure above)
source_array = source()
# inserted in model frame
source_in_scene_array = scene_.evaluate_source(source)
# as it appears in observed frame
source_as_seen = obs.render(source_in_scene_array)
# for imshow: don't interpolate the pixels, put origin to bottom
plt.rc("image", interpolation="none", origin="lower")
fig, axes = plt.subplots(1, 3, figsize=(10, 4))
axes[0].imshow(sc2.plot.img_to_rgb(source_array, norm=norm))
axes[1].imshow(sc2.plot.img_to_rgb(source_in_scene_array, norm=norm))
axes[2].imshow(sc2.plot.img_to_rgb(source_as_seen, norm=norm))
plt.show()
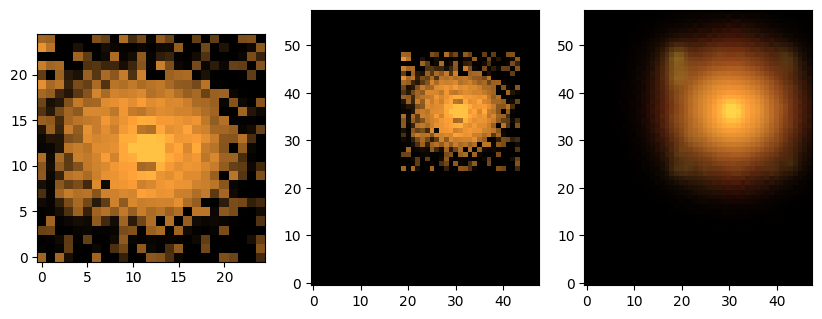
We also provide a function to create all of these source images:
sc2.plot.sources(
scene_,
norm=norm,
observation=obs,
show_model=True,
show_rendered=True,
show_observed=True,
show_spectrum=True,
add_labels=False,
add_boxes=True,
);
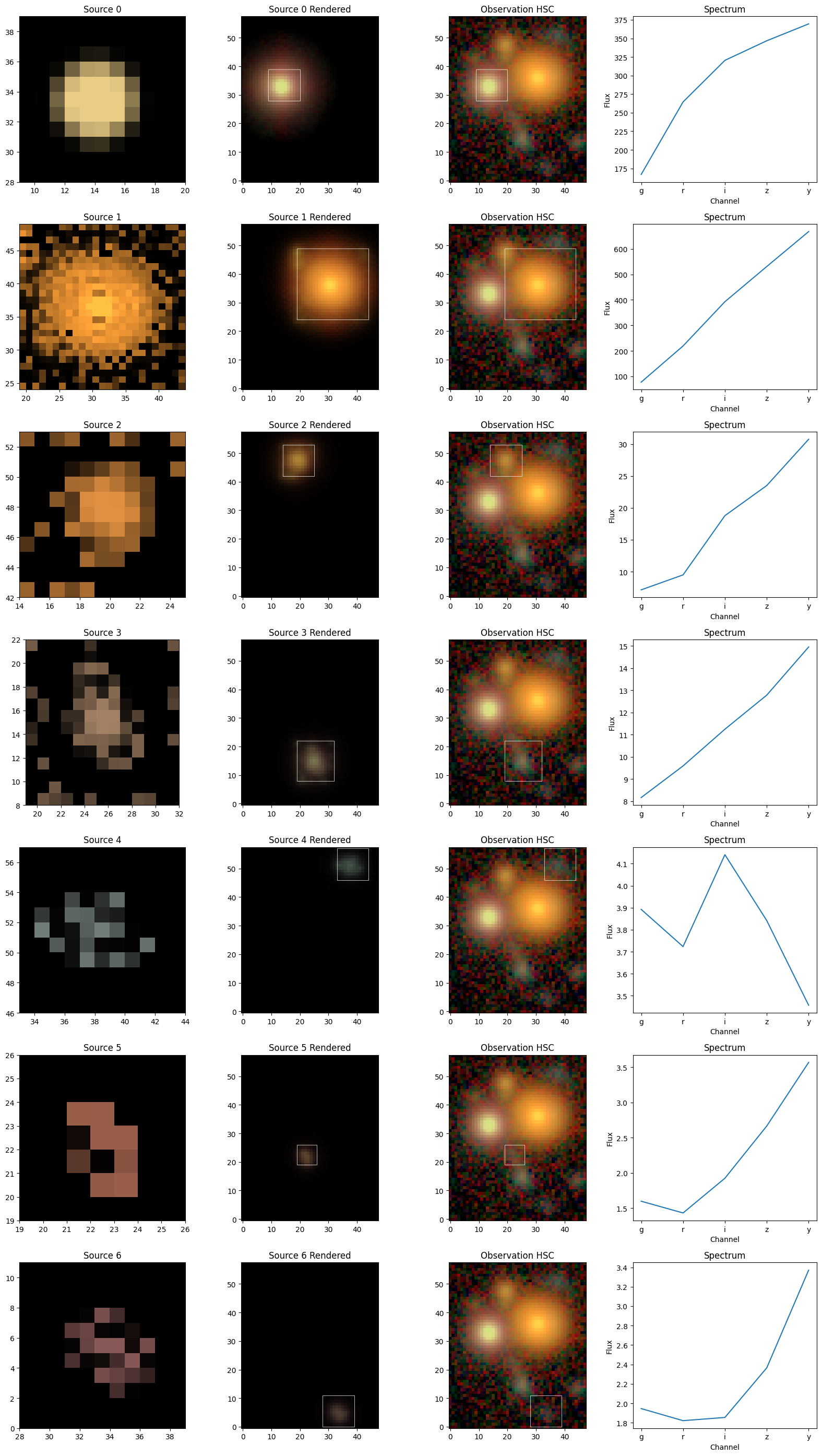
The model of object 0 assumes the simple Gaussian shape of the model PSF, which is the internal representation of a point source.
But it’s noticeable that all other sources show pixel patterns that don’t seem right. Some of them pick up flux from other sources (especially source 1) or noise (sources 4-6). What we see here is the limitation of non-parametric models: they can fit anything, but the likelihood may not have enough information to constrain all of these degrees of freedom. More/stronger constraints or priors can help, and we will describe their use in a separate tutorial. Another option is the addition of a model-free regularizer, e.g. PairSimilarity, which we demonstrate in the LSBG tutorial.
Source Measurements#
As shown above, source models are generated in the model frame (dah…), from which any measurement can directly be made without having to deal with noise, PSF convolution, overlapping sources, etc.
For instance, the color information in these plots stems from the spectrum, i.e. the per-band amplitude, which are computed from the hyperspectral model by integrating over the morphology. The source spectra plots in the right panels above have done exactly that. The convention of these fluxes is given by the units and ordering of the original data cube.
print(f"----------------- {channels}")
for k, src in enumerate(scene_.sources):
print(f"Source {k}, Fluxes: {sc2.measure.flux(src)}")
----------------- ['g', 'r', 'i', 'z', 'y']
Source 0, Fluxes: [166.92531 264.46338 320.43146 346.79205 369.49612]
Source 1, Fluxes: [ 77.159424 219.02937 392.6757 530.7709 667.69977 ]
Source 2, Fluxes: [ 7.150646 9.494683 18.776455 23.499784 30.744814]
Source 3, Fluxes: [ 8.161062 9.58582 11.241827 12.777564 14.945986]
Source 4, Fluxes: [3.8923929 3.723444 4.1409316 3.8413372 3.456811 ]
Source 5, Fluxes: [1.5972825 1.4305847 1.923718 2.6655524 3.5681393]
Source 6, Fluxes: [1.9461381 1.8218665 1.8549378 2.365532 3.3711326]
Other measurements (e.g. centroid) or Moments are also implemented:
g = sc2.measure.Moments(scene_.sources[1])
print("Source 1 ellipticity:", g.ellipticity)
Source 1 ellipticity: [[ 0.08012365 0.08012361 0.08012371 0.08012357 0.08012365]
[-0.11883204 -0.11883204 -0.11883204 -0.11883204 -0.11883201]]
All of these measurements are ordered by channel, so the ellipticity above is listed as [[e1_g, e1_r, e1_i, e1_z, e1_y],[e2_g, e2_r, e2_i, e2_z, e2_y]]. That they are all the same should not come as a surprise: For single-component models, there is no variation of the morphology across the channels.
Save and Re-Use Model#
To preserve the model for posterity, individual sources (or their sub-models) or entire scenes can be serialized into a HDF5 file:
import scarlet2.io as io
scene_id = 35
filename = "hsc_cosmos.h5"
io.model_to_h5(scene_, filename, id=scene_id, overwrite=True)
The stored model be loaded in the same way. Every source can be utilized as before.
scene__ = io.model_from_h5(filename, id=scene_id)
sc2.plot.scene(scene__, observation=obs, norm=norm, add_boxes=True);
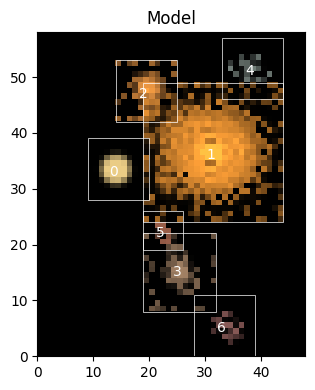
We will now add two more sources to account for the largest residuals we have seen above. As we don’t know their location accurately, we allow the fitter to shift/recenter the sources.
# enter the context of the scene to create new elements
with scene__:
# add two marginally detected sources at their approximate locations
yx = [(14.0, 44.0), (42.0, 9.0)]
for center in yx:
center = jnp.array(center)
# initialized like a point source
spectrum = sc2.init.pixel_spectrum(obs, center)
morph = sc2.init.compact_morphology()
sc2.Source(center, spectrum, morph)
# need to remake the parameter structure including the new sources parameters
with sc2.Parameters(scene__) as params:
# we could repeat the parameter definition from above
# or: copy the parameters from scene
params.update(scene.parameters)
# define Parameter(s) for the new sources
for i in range(len(scene.sources), len(scene__.sources)):
sc2.Parameter(
scene__.sources[i].spectrum,
name=f"spectrum:{i}",
constraint=constraints.positive,
stepsize=spec_step,
)
sc2.Parameter(
scene__.sources[i].morphology,
name=f"morph:{i}",
constraint=constraints.unit_interval,
stepsize=morph_step,
)
scene___ = scene__.fit(obs, max_iter=maxiter, e_rel=1e-4)
Fit validation results for observation HSC:
[000] INFO The model fit is good. | Context={'chi2': Array(1.144946, dtype=float32)})
[001] WARN The chi-square in the box for source 0 is acceptable, but not optimal. | Context={'chi2_in': Array(2.286987, dtype=float32), 'source': 0})
[002] INFO The chi-square in the border for source 0 is good. | Context={'chi2_border': Array(0.9683097, dtype=float32), 'source': 0})
[003] INFO The chi-square in the box for source 1 is good. | Context={'chi2_in': Array(1.4998407, dtype=float32), 'source': 1})
[004] INFO The chi-square in the border for source 1 is good. | Context={'chi2_border': Array(1.0754389, dtype=float32), 'source': 1})
[005] INFO The chi-square in the box for source 2 is good. | Context={'chi2_in': Array(0.92578435, dtype=float32), 'source': 2})
[006] INFO The chi-square in the border for source 2 is good. | Context={'chi2_border': Array(1.1385239, dtype=float32), 'source': 2})
[007] INFO The chi-square in the box for source 3 is good. | Context={'chi2_in': Array(0.99179876, dtype=float32), 'source': 3})
[008] INFO The chi-square in the border for source 3 is good. | Context={'chi2_border': Array(0.927294, dtype=float32), 'source': 3})
[009] INFO The chi-square in the box for source 4 is good. | Context={'chi2_in': Array(0.8417383, dtype=float32), 'source': 4})
[010] INFO The chi-square in the border for source 4 is good. | Context={'chi2_border': Array(1.0104257, dtype=float32), 'source': 4})
[011] INFO The chi-square in the box for source 5 is good. | Context={'chi2_in': Array(0.9925889, dtype=float32), 'source': 5})
[012] INFO The chi-square in the border for source 5 is good. | Context={'chi2_border': Array(0.99313873, dtype=float32), 'source': 5})
[013] INFO The chi-square in the box for source 6 is good. | Context={'chi2_in': Array(0.9877089, dtype=float32), 'source': 6})
[014] INFO The chi-square in the border for source 6 is good. | Context={'chi2_border': Array(1.0549594, dtype=float32), 'source': 6})
[015] INFO The chi-square in the box for source 7 is good. | Context={'chi2_in': Array(0.8061653, dtype=float32), 'source': 7})
[016] INFO The chi-square in the border for source 7 is good. | Context={'chi2_border': Array(0.9745486, dtype=float32), 'source': 7})
[017] INFO The chi-square in the box for source 8 is good. | Context={'chi2_in': Array(0.86392105, dtype=float32), 'source': 8})
[018] INFO The chi-square in the border for source 8 is good. | Context={'chi2_border': Array(1.3140569, dtype=float32), 'source': 8})
We can see that the fit is slightly better than before. Let’s have a look at the new model:
sc2.plot.scene(
scene___,
obs,
norm=norm,
show_model=True,
show_rendered=True,
show_observed=True,
show_residual=True,
add_boxes=True,
);
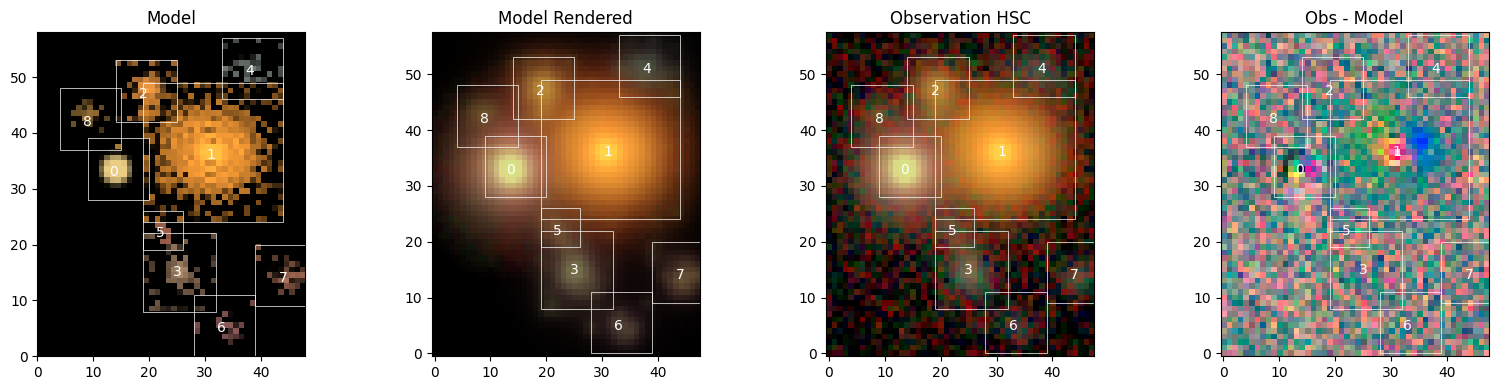
We can see the two new sources 7 and 8, and that most of the other features are very similar to before. As expected, the residuals have visibly improved where we added the source and are now dominated by a red-blue pattern in the center of source 1, which we should probably fit with 2 components.
Notice in plot on the right, source 0 has a slight color dipole close to the center. If you’ll recall when we created the Observation object a validation check produced an error that indicated misaligned PSF centroids. That PSF centroid misalignment is the likely cause of the dipole.